Inside Juno: Building a Local AI Voice Layer for Mac
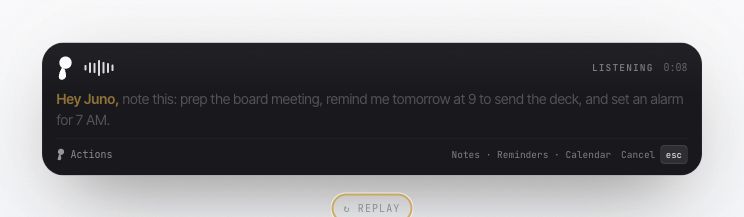
Hey Juno!
Juno began with a simple bet: voice should be a first-class way to write on your computer, and it should not require sending your work, meetings, drafts, or corrections to someone else's server.
The hard part was that speech to text was never the full problem. If all Juno did was record audio, run a transcription model, and paste text into the focused app, it would have been a weekend demo. The useful product is the loop around that model: live transcript, final cleanup, selected-text rewrite, secure-field suppression, native insertion, local memory, and recoverable failure states.
That is the technology behind Juno: a local runtime and a native Mac shell designed together, with model calls placed only where they earn their keep.
The Constraint That Shaped Everything
We wanted Juno to be free to use without an account, without a cloud transcription meter, and without a server becoming the product's real dependency. That meant the expensive work had to run on the user's Mac.
Building local AI apps is hard. Ask Apple.
The current stack is built for Apple Silicon. The packaged runtime uses MLX Whisper large-v3-turbo for speech recognition, Qwen3-4B Instruct through MLX LM for writing and planning, and a smaller Qwen3-0.6B lane for lighter correction work in the packaged engine. The shell is a native macOS app. The engine is a local Python process. The boundary between them is a local socket, not a network service.
That architecture gives us the product property we care about most: after the one-time model download, everyday dictation can run locally. Audio, transcripts, corrections, vocabulary, and local memory do not need to leave the machine for normal use.
It also made the engineering problem much less forgiving. A model that hallucinates during silence is not a benchmark artifact when it appears in a live HUD. A planner that guesses an action from "Hey Juno" is not clever; it is data loss if the dictated text never gets pasted. So we stopped treating Juno as a single model problem and built it as a set of narrow, testable lanes.

One Utterance, End To End
The easiest way to understand Juno is to follow one utterance through the system.
The user presses the shortcut. The Mac shell, not the model, makes the first decision. It checks whether Juno is allowed to listen, whether Accessibility access is available, which app is frontmost, whether the focused field appears secure, whether text is selected, and whether the current target can accept insertion. That capability snapshot is pinned for the session because privacy policy should not depend on a late model decision.
Then the shell opens the microphone and streams audio to the local engine. Voice Activity Detection decides when speech has started. The preview lane receives rolling audio windows and decodes them with MLX Whisper. The preview manager filters silence failures, compares successive hypotheses, commits only agreed words, and keeps the unstable tail separate.
While the user is speaking, the HUD is driven by that preview lane. The writer model is intentionally not rewriting the live transcript. The live transcript should answer one question: what did I probably just say? It should not polish, summarize, plan, or infer intent while the user is still talking.
When the user releases the shortcut, the final lane runs over the utterance. That result enters the text pipeline: normalization, correction, action detection, rewrite routing, snippet expansion, memory packet construction, and insertion. If the utterance is plain dictation, Juno stays on the plain dictation path. If the user selected text and asked for a rewrite, the writer gets a bounded edit task. If the user asks for an action, the action subsystem validates intent before touching Notes, Reminders, or Calendar.
Finally, the shell inserts the result or shows a recoverable fallback. Successful commits can update local history and memory, unless policy says they cannot. Secure-field sessions turn off context capture, learning, history, recording, and paste.
That is the shape of the product: every utterance carries audio, text, context, policy, and recoverability through the same local loop.
Why Live Transcription Was The Hardest Part
A final transcript can wait until the user stops speaking. It can run over complete audio, reconsider the whole utterance, and produce a clean answer. A live transcript has to show something while the user is still talking. It is forced to decode partial audio, often ending mid-word or mid-thought, then decide which words are safe to show as real.
If the HUD lies, users notice immediately. If it rewrites text that already looked committed, users lose trust even faster. Juno splits live text into two concepts: committed text, which is stable enough to show as the user's actual speech, and tail text, which can be visually useful but remains provisional.

The core algorithm is a LocalAgreement-style commit loop. Consecutive Whisper hypotheses have to agree before text can graduate into the committed region. The unstable tail can move. Committed text should not.
We wrote a longer technical piece dedicated to this engineering feat: Why Live Transcriptions Are Hard.
Why Whisper Owns Speech
Juno has gone through staged faster-whisper paths, MLX Whisper paths, Qwen-based speech ideas, smaller local language models, and larger local writing models. The direction that survived was simple: use the best local speech model for speech, then use language models only where language reasoning is actually needed.
For the current Apple Silicon path, that means mlx-community/whisper-large-v3-turbo for preview and final ASR. Whisper does not solve everything. It can hallucinate around silence, produce plausible continuations near the end of a window, and miss proper nouns without help. But it gave Juno the right local tradeoff: strong speech recognition, practical Apple Silicon performance through MLX, and predictable enough behavior to build deterministic safety systems around it.
- Whisper owns speech recognition.
- LocalAgreement owns live commit safety.
- Deterministic normalizers own simple formatting and numeric cleanup.
- Qwen owns bounded writing, rewriting, and planning tasks.
- The Mac shell owns insertion, privacy gates, permissions, and native actions.
The Final Path Is Not The Live Path
The final path has more information than the live path. It has the full utterance audio, committed preview text, app context, selected text, local memory, snippets, and the session privacy policy. It can decide whether this was plain dictation, a rewrite, a command, or a combination that should be rejected safely.
The first versions tried to make the final path too smart. It is tempting to send every utterance to a 4B local model and ask for a perfect plan. That works in demos. It is dangerous as a writing tool.
- Long plain dictation should not wait for a planner. If the user speaks a paragraph with no command structure, the product should paste the paragraph.
- Wake words are not consent. Action intent needs a verb, an object, and enough evidence from the user's words to execute.
- Rejected actions must not eat dictated text. If the action lane cannot safely execute, the transcript still belongs to the user.
- Paste is a product guarantee. If direct insertion is blocked, Juno falls back to Copy Ready instead of losing the result.

The model can propose. The product decides.
Latency Is Architecture
Local models make latency visible. A cloud voice product can hide some architectural sins behind server-side capacity. A local app has the user's Mac, the user's current memory pressure, and the user's patience. If a model unloads between utterances, every pause becomes a cold start. If two heavy lanes fight for GPU memory, the HUD stutters.
That is why Juno's model residency policy became part of the product design. The packaged engine keeps the preview service resident and keeps the writer resident by default because repeated Qwen3-4B cold starts were too expensive for an interactive dictation product on 16GB+ Macs. The writer backend also uses static-prefix KV cache reuse so repeated system prompts do not keep paying the same cold prefill cost.
Juno has at least four latency budgets: first live words in the HUD, stable committed words during speech, final transcript after release, and native insertion or action completion. Optimizing one can hurt another, so each budget has to be treated separately.
The Mac Shell Is Part Of The AI System
Juno is not just a Python engine. The native shell is part of the AI system because it owns the user's real environment. It knows which app is frontmost, whether Accessibility permission is available, whether a text field is focused, whether selected text exists, whether the field looks secure, and whether the result should be inserted, copied, or blocked.
That information changes the model path. Secure fields force capture, context, history, learning, recording, and paste off. App-blocked or remote-control contexts fall back to copy behavior. Selected text changes a command from new dictation into a replace operation. A Notes action has to be executed through the native action executor, not hallucinated as a sentence.
Personalization Without Training On The User
Dictation gets better when it knows your world. Names, project terms, snippets, style preferences, and recent corrections matter. But personalization becomes a privacy problem if it means uploading user text or continuously training a remote profile.
Juno's personalization is local and bounded. The memory layer stores user-managed vocabulary, replacements, learned corrections, session entities, snippets, and style cards. At runtime, it builds a compact serving packet that can be used by ASR biasing, normalization, snippets, and writer prompts. The model weights do not change.
Useful Actions, Never Magic
Voice actions make Juno feel like more than dictation: create a note, make a reminder, set an alarm. They also change state outside the text field, which means they need stronger gates than plain writing.
Juno treats actions as a constrained subsystem, not open-ended agency. Deterministic grammar handles common forms, and the model-backed extractor works inside a schema. It must return an allowed action kind, valid fields, evidence from the utterance, and enough confidence. Invalid action plans are rejected, not improvised.
The Failure Model Became A Feature
One of the biggest shifts was moving from make the model better to make failures explicit. The microphone may be unavailable. Live preview may hallucinate during silence. The writer may change content too aggressively. An app may refuse paste. Accessibility permission may disappear. If those failures collapse into nothing happened, the product is impossible to trust.
Juno's HUD state model, history records, runtime health files, local traces, and copy fallback all came from that realization. The app needs to tell the user what happened. The engineering team needs to reconstruct what happened. And the system should bias toward preserving user text even when the smart path fails.
This is the shape we think local AI products will keep converging toward: not one model doing everything, and not a thin app around a cloud endpoint, but a real product runtime with models as components inside it.
Why This Matters
The visible promise of Juno is simple: press a key, talk, and Juno types.
The technical promise underneath it is broader. A high-quality voice-writing product does not have to be a metered cloud service. It can run locally on a modern Mac. It can use strong open models. It can keep user speech and writing private by design. It can personalize without training on the user. It can use language models for the parts where language models help, while keeping the critical path grounded in deterministic systems.
That is why we are building Juno in the open. We want local voice input to feel normal: not like a novelty feature, not like a privacy compromise, and not like a cheaper version of a cloud product. We want it to feel like a native layer of the computer, always there when you need to write, quiet when you do not, and understandable when something goes wrong.
What Still Feels Unfinished
The honest version is that Juno is not done. Actions need deeper follow-up behavior. Latency can keep improving. And we are watching the Apple-native stack carefully: SpeechAnalyzer, Foundation Models, Core ML, MLX, App Intents, Spotlight, and future Core AI surfaces all matter if they make the local loop faster, safer, more private, or easier to verify.
But the foundation is now clear. Juno is a local voice-writing system. The "AI" is not one model. It is the whole loop: audio, preview, finalization, writing, action safety, memory, privacy, native insertion, observability, and recovery.
That is the part we are most proud of.
Stop Typing, Start Speaking
If you would like to contribute to Juno or explore the depth of the work, start with the source and the product docs. We will be releasing a few more products this month at Cassini Research.